
singularity 是广泛应用于前沿HPC服务商的容器化应用,打包成sif格式的容器可以在同架构安装了singularity的任意linux系统下运行。如,通过singularity容器可以在centos8下运行centos6时代的软件,极大的保证了计算的可靠性和可重复性。下例为集群g16的singularity def打包脚本,供有需求的大家参考: 本例打包的singularity sif文件位于/mnt/softs/singularity_sifs/g16_openmpi.sif, 使用以下命令即可调用:
Monthly Archives: April 2023
12 posts
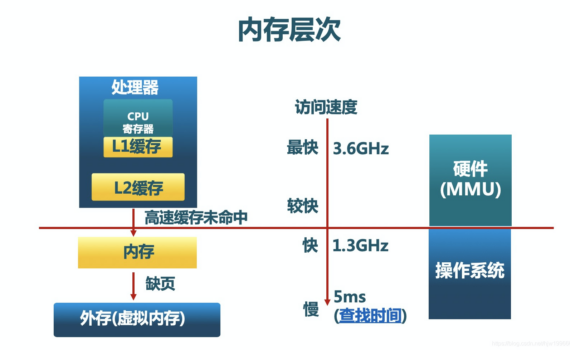
相比CPU,内存(Memory)是更复杂的硬件资源,原因在于操作系统对两种资源的处理方式不一样。虽然CPU和Memory都可被多个进程分时共享,但共享的代价差别很大,这在很大程度上影响了用户对两种资源的使用。 操作系统的内存魔法 为了回答用户关于内存使用的问题,我们需要先了解操作系统的内存管理机制。 内存分层体系 冯诺依曼计算机体系结构的要点是存储程序计算,其中内存承载程序指令和数据,是关键的性能影响因素。现代操作系统采用内存分层体系,利用程序执行和内存访问的局部性原理最大化高速内存设备的利用率,优化系统整体性能。下图展示了内存分层体系结构: 这个体系中各级存储设备的性能差别有多大呢?我们祭出一组Google大牛Jeff Dean在演讲中公布的性能数字: 从上面的性能数字不难推测,如果我们想办法将最有可能被马上访问的热数据加载到内存,将冷数据存储在相对低速设备中,可以在保持现有成本的前提下最大化用户的性能体验。这就是内存分层体系的指导思想。这个思想暗含的前提是计算机程序运行具有局部性特征。什么是局部性呢?通俗的说就是刚刚执行过的程序指令很大概率被再次运行,刚被访问过的内存地址很大概率又会被访问。在这个假定下,操作系统将很久没有被访问的数据从内存交换到硬盘上,释放出内存空间承载访问频率高的数据,实现了硬盘级别的成本和内存级别的性能。 为了实现这个策略,操作系统采用了虚实策略, 即将内存分为虚拟内存和物理内存。程序猿在C、C++、Java中malloc或者new分配的都是虚拟内存,是一个逻辑地址区域,并没有物理内存与之对应。这些区域只要不访问,就不会给它们映射物理内存。一旦程序访问未被映射的虚拟内存区域,就会触发硬件的缺页中断page […]

应用程序运行于操作系统之上。现在操作系统,无论是Linux、Unix或Windows,分时复用是基本的CPU调度方式。本文仅就Linux操作系统,结合Achelous平台,探讨如何高效使用CPU资源。 常见的灵魂拷问 资源cpus在物理上对应什么? Achelous平台上用户申请的CPU资源都是逻辑CPU核,并不一定和任何物理CPU、核心或者超线程对应。如果没有打开核的超线程选项,物理CPU的每个核在操作系统中体现为一个逻辑CPU核。如果打开了超线程技术,每个核会有两个物理线程,每个线程在操作系统中就是一个逻辑CPU核。 例如在Linux上运行命令cat /proc/cpuinfo可以看到如下的信息: [root@Cc1Apc ~]# cat /proc/cpuinfo […]
MPI是高性能计算常用的实现方式,它的全名叫做Message Passing Interface。顾名思义,它是一个实现了消息传递接口的库。MPI作为编程库很丰满,作为计算框架很骨感。它的好处在于一切自己动手,不利也在于一切全靠自己。 本文的目的不是探讨如何使用MPI,MPI标准是这方面最有参考价值的文档。本文笔者仅仅讨论它在并行编程上的特点,帮助用户决定何时或在何种场景下使用MPI。 什么是MPI? MPI是一个跨语言的通讯协议,支持高效方便的点对点、广播和组播。它提供了应用程序接口,包括协议和和语义说明,他们指明其如何在各种实现中发挥其特性。从概念上讲,MPI应该属于OSI参考模型的第五层或者更高,他的实现可能通过传输层的sockets和Transmission Control Protocol (TCP)覆盖大部分的层。大部分的MPI实现由一些指定的编程接口(API)组成,可由C, C++,Fortran,或者有此类库的语言比如C#, […]
在计算密集型或者数据密集型的应用场景,多机并行处理是提升性能的常用方法。并行编程不仅仅是一个编程问题,它涉及到数据访问、多机通信和资源调度,应用开发人员不可能从头造轮子解决所有问题,借助于编程框架是不可避免的趋势。究竟框架如何提升并行处理的效能呢?本篇我们聊聊这个话题。 并行如何提升计算效率? 分而治之是王道 计算机算法中常常将一个大问题分解成若干个小问题来解决,这就是所谓的分治法(Divide-Conquer)。如果不同的小问题可以交由单台机器的N个CPU(泛指逻辑CPU,包括CPU、核或者超线程),或者更进一步交给多台机器的N个CPU,理想情况下期望的运行时间可能缩短到1/N。之所以说是理想,是因为实际运行时间由下面几个因素决定: 由上述公式可知,如果系统中必须有50%的代码串行执行,那么系统的最大加速比为2。 计算机体系提升并行的方式 分布式计算是从并行计算机的时代演化来的。我们花点时间介绍一下传统并行计算机的实现模式,以此为基础理解分布式并行计算会有帮助。笔者认为并行的基础是数据并行。这个数据指文件,也可以是内存或者寄存器的数据。如果没有数据并行,那意味着操作之间或者毫无关系(从而直接分解),或者必须严格串行。如果是后者,就不可能有并行可言。 在传统的计算机体系中,数据并行有两种实现路径: 在分布式并行处理的场景中,我们会看到类似SIMD和MIMD的模式。 资源瓶颈驱动问题分解 […]

容错是大规模数据系统和计算系统的必备功能,不能容错的分布式系统基本没有可用性。大家可能觉得高质量的系统错误率没有那么高,实质上系统的故障率总是随着系统规模和复杂程度增加。笔者读书的时候曾经听过一位参与过先进飞行控制系统设计的专家讲课。这位专家有一句原话是说飞机大多是带故障飞行的。笔者很多研究无人机的师兄们都有意无意的避免坐飞机。笔者坐飞机也会再三确认购买保险 🙂 这不是吓唬大家,只是为了说明容错与我们息息相关。本篇我们来聊聊系统容错的方方面面。 1. 可靠性从哪里来? 1.1 安全、可靠与可用 安全(safety)、可靠(reliable)和可用(available)是我们常用的几个词汇。安全通常指避免灾难的能力,可靠指的是无故障提供指定功能的能力,可用指的是某个时间段系统能够正常运行。安全与可靠容易区分。举个例子来说,一架飞机坏了停在地上,它是安全的,因为它不可能引发灾难,但是不可靠,因为它无法完成飞行任务。可靠和可用的区别是什么呢?再举一个例子,你把钱存在银行里,晚上银行下班了,你没法通过柜台取钱。你的资产没有问题,银行具备可靠的保管你的资产的能力,但是它的服务不是7 x 24 […]
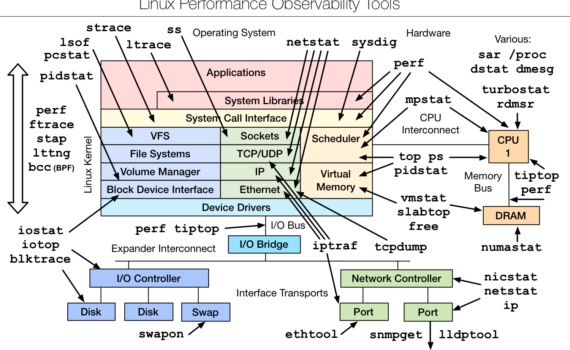
有句成语说“工欲善其事必先利其器”,系统问题纷繁复杂,需要完善的工具、方法和系统来帮助定位和解决。操作系统级别的机制和工具是首要条件,是后续分析和自动化的基础。打铁先得锤子硬。本篇笔者结合自己的经验,和大家聊聊分析系统问题的工具和方法。 工具只提供数据不提供答案 无论是通过命令行手动分析,还是运维系统自动分析,包括玄之又玄的智能运维(AIPOS),基础都是数据。差别只是做分析和决策的是人还是程序。在真实的数据密集型和计算密集型的生产环境中,任何机制或者工具都不可能采集系统所有的事件,所以数据不是日志,它在本质上是系统行为和状态在某个层次的粗粒化。例如iostat看硬盘设备的读写带宽和占用率,返回的是一个时间段的宏观统计值,使用者需要根据经验或者系统的实现机制去分析潜在的原因。 事件、状态或性能? 分析目的不一样,采用的工具、方法和代价各不相同: 数据采集对系统的影响 数据收集的首要问题是数据收集的代价,即数据收集对生产系统的影响程度如何。不同工具因为其实现方式不一样,对系统造成的影响各不相同。iotop或者iostat等工具的数据收集在目标代码段执行过程中,或者状态切换的时候进行,代价较小,但是提供的信息粒度相对固定。dtrace或者systemtap 等工具支持用户插入自己的分析代码,会给系统造成一定程度的性能影响。这些工具通常提供选项控制采样频率或者尺度,使用者需要根据具体情况选择。 Linux提供了哪些工具? Linux系统集成了大量的监控和分析工具帮助用户解决问题,大家根据需要自行选择服用。这些都是开发、调试、运维、杀人、放火必备技术。 […]

IT江湖上流传有一种说法,说的是“编译器和操作系统是计算科学的皇后”(不好意思,两个皇后)。编译器追求的是编程艺术,无数先贤发明编程语言获得图灵奖。如果说编译器是珠峰上的明珠,那笔者认为操作系统就是喜马拉雅山的垫脚石。操作系统没有编译器那么高大上,没有特别高级的算法,也没有让人眼前一亮的漂亮功能。它只是为所有可能的程序提供高效稳定的运行环境。单想做到这一点就足以耗尽无数系统程序猿的心血,却往往换不来一句好评。 刚入行时,听一位老司机说:“我们搞计算机的和木匠瓦匠是一回事,都是手艺人”。计算机科学与物理化学不一样,本质上不发现自然界的未知规律,它的目标是用已有的工具或者创造新工具解决已知的问题。它更像是经济学,追求的是解决问题的效率。在计算机领域的所有手艺中,系统开发(泛指操作系统内核、存储、计算基础架构等系统级工程)是“两头堵”的艺术,系统程序猿们整天忙着拆东墙补西墙,众口难调调众口。 写了很多编程宝典的侯捷说:“源码之前,了无秘密”。笔者想说,这句话可能不适用于系统软件。系统软件一旦运行,往往展现出复杂的动态行为,万“相”丛生,非“代码”两字足以囊括。笔者借用一个名词,称它是动力系统,说明其动态演化的特点。笔者在本篇和大家聊聊这些动态系统的机制,以及它们对真实的计算系统或者业务的决定性影响。 不会看病的程序猿不是好员工 任何一个产品交付给用户使用后,自然形成一个责任边界,即哪些责任由产品提供商负责,哪些责任由用户负责。实际情况是怎么样的呢?供需不平等决定了甲乙双方地位实质上不对等,用户往往进行有罪推定,而产品提供方则需要自证清白。基础架构产品(存储或者计算),他们对应用程序的运行时行为有间接但是决定性影响,责任边界更难划分。做系统的工程师都得会两手:一手给自己找茬(程序的Bug到底在哪里?),一手替别人看病(这是你的问题,不是我的Bug)。如果问题出在企业的生产环境,工程师更得如履薄冰,小心翼翼。 线上运维之“悬丝诊脉” 我们从小说和影视剧中常常可以看到“悬丝诊脉”的情节。神医把丝线的一头搭在贵妃的手腕上,另一头则由自己掌握。神医必须凭借着从悬丝传来的手感猜测、感觉脉象,诊断疾病,因为男女授受不亲,贵妃的身体更是碰不得。企业生产环境的应用跟贵妃一样,乙方能不碰是尽量不去碰的。例如用户一个典型的组装植物基因组的程序,经常得跑上几个星期,疯狂使用内存或者存储。如果跑到第十天还没有结束,用户会理直气壮地问“为什么还没有结束啊?系统出问题了吧?”。这个时候我们的工程师就得上去诊断。用户的程序是不可能停的,也不能调整配置做实验,或者调试一下存储。如果用户的程序被你弄挂了,就更说不清楚了。工程师们既要帮用户解决问题,还得离这个程序远远的。这就是典型的悬丝诊脉嘛。 当然也有乙方是比较生猛的。我们曾经在一个公有云的大厂上跑一个流程,运行了几天,程序卡住了。原因很简单,从两个不同的机器看一个目录,内容不一样。做过分布式存储的同志们都知道,这是数据不一致了,大概率是分布式锁的问题。乙方上去折腾了几天,搞不定。最后他们的支持工程师来了个猛的,提出把挂载点umount/mount解决问题,我们直接就傻眼了:“2B的工程师们不可以这么生猛吧?”。这显然不是典型的系统工程师啊。 学会当系统工程师 系统工程师这个说法笔者刚开始参加工作的时候从一个洋人大老板那里听来的,大体意思是从硬件到软件,从内核到用户态程序,从代码到脚本都得精通。这个系统的所有问题都是你的,需要你去搞定。当时觉得老板你真会忽悠人干活。后来自己参与存储创业,才明白了这个道理。为什么对工程师这么要求呢?因为一个存储或者计算系统是一个端到端的全栈解决方案。存储不等同于硬件,计算不等同于调度。用户的应用出了问题,你没法直接说问题不是你的。你得上去从头到脚的分析,直到证明这是应用程序自己的问题。在这个过程中,还要保证应用不受影响。 […]

无论是基于虚拟化的公有云还是基于容器的容器云(例如架在公有云上的k8s),都不是天然为HPC或者计算类业务优化的基础架构。那么“云”和“计算”理想的结合是什么呢?笔者认为应该是计算云。大家如果认为笔者前两篇文章是在挑刺的话,那这篇文章就尝试开个药方。 计算云是什么? 笔者所谓的计算云指的是为计算业务优化的类云基础架构,它强调用云的方式解决计算问题,而不是将“计算”搬到现有的公有云或者容器云上。目前公有云或者容器云(例如k8s)上的HPC解决方案本质上都是将现有的HPC方案虚拟化或容器化,以虚拟机或容器替代物理机。这些做法是为了将公有云资源卖给计算用户,并没有改进计算业务本身。 从用户的角度说,计算云是什么样的呢?笔者认为计算云应该具备下面几个特征。 1. 计算即服务 计算云提供的应该是端到端的计算服务,而不是资源服务。以一个传统环境下的HPC用户举例。HPC集群各个计算节点挂载了分布式文件系统,用户(或者系统管理员)将计算程序安装到分布式文件系统。用户登录到集群的登录节点,通过qsub投递一个单机计算任务,或者通过mpiexec提交一个MPI计算任务。调度系统(例如SGE、PBS、Slurm等)分配合适的计算资源,完成用户的计算任务。如果把HPC集群搬到云上或者容器里,使用方式仍然类似。系统管理员拉起一个HPC集群,普通用户登录集群使用计算服务。 现在问题来了。如果这个用户需要混合使用MPI、Hadoop、Tensorflow怎么办呢?系统管理员需要拉起三套集群,分别做三种计算。用户需要登录到三套不同的系统中提交任务。这三套系统的使用频率、负载程度不一样,系统管理员不可能实时动态管理集群来确保资源利用率。系统管理员以容器云的方式将HPC集群容器化是一种计划经济,没有市场经济的效率。计算应该由用户主导,按需分配。按需分配意味着程序化自动调度。基于k8s的Volcano解决问题的方式是让普通用户使用k8s模版提交任务。MPI用户需要提交服务模版去启动一组运行sshd服务的容器,然后启动一个运行mpiexec程序的容器。这种方式将系统管理员的工作转移到了用户身上,用户需要学习使用k8s。用户真正关心的是他自己的MPI程序,不是k8s,也不是运行sshd容器。造成这个问题的原因是k8s只是一个PaaS解决方案,本质上提供的是资源服务,不是计算服务。 真正的计算即服务要求用户不需要做与自己计算无关的事情。计算集群提供一些登录容器或者服务器,用户登录服务器安装软件到分布式文件系统,或者将软件打包成容器。用户根据自己的需要在登录节点通过qsub或者mpiexec提交作业,指明作业需要的资源和数据。计算云根据任务的类型,按需分配资源,构建HPC、Hadoop或者Tensorflow集群完成计算。计算过程中的资源如何分配,集群如何部署和销毁,数据如何共享是计算云内置的服务,不应该有用户参与。用户只需提交数据和程序到计算云,然后等待计算结果。 2. […]